
DC_OCEAN: an open-source algorithm for identification of duplicates in ocean databases
Published in Frontiers of Marine Sciences, 2024
A high-quality hydrographic observational database is essential for ocean and climate studies and operational applications. Because there are numerous global and regional ocean databases, duplicate data continues to be an issue in data management, data processing and database merging, posing a challenge on effectively and accurately using oceanographic data to derive robust statistics and reliable data products. This study aims to provide algorithms to identify the duplicates and assign labels to them. We propose first a set of criteria to define the duplicate data; and second, an open-source and semi-automatic system to detect duplicate data and erroneous metadata. This system includes several algorithms for automatic checks using statistical methods (such as Principal Component Analysis and entropy weighting) and an additional expert (manual) check. The robustness of the system is then evaluated with a subset of the World Ocean Database (WOD18) with over 600,000 in-situ temperature and salinity profiles. This system is an open-source Python package (named DC_OCEAN) allowing users to effectively use the software. Users can customize their settings. The application result from the WOD18 subset also forms a benchmark dataset, which is available to support future studies on duplicate checks, metadata error identification, and machine learning applications. This duplicate checking system will be incorporated into the International Quality-controlled Ocean Database (IQuOD) data quality control system to guarantee the uniqueness of ocean observation data in this product.
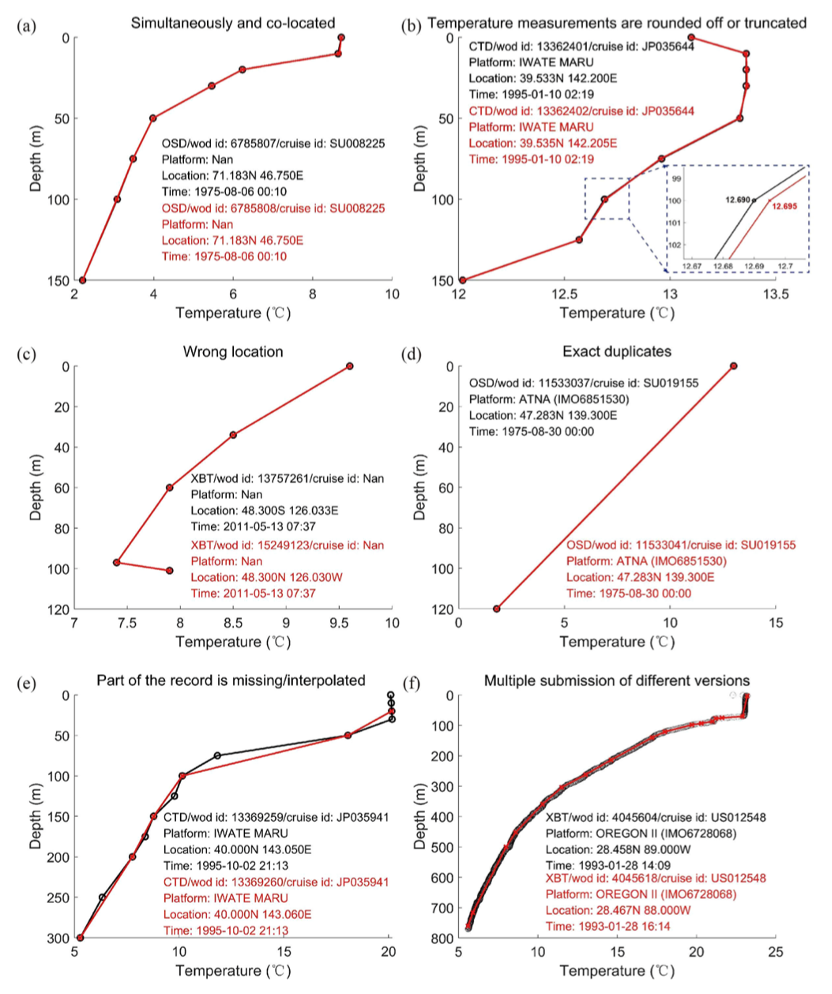
Figure. Example of some duplicated pairs.
**If you are interested, do not hesitate to read this paper and use the codes (https://github.com/IQuOD/duplicated_checking_IQuOD) for your study. **The code (DC_OCEAN; https://github.com/IQuOD/duplicated_checking_IQuOD)) is available as an open-source Python package under the Apache-2.0 license (https://pypi.org/project/DC-OCEAN/).
Please also feel free to circulate this paper to those who might interested in our work.
We are also very welcome for any feedbacks or suggestions!
Citation: Song X†, Tan Z†, Locarnini R, Simoncelli S, Cowley R, Kizu S, Boyer T, Reseghetti F, Castelao G, Gouretski V, Cheng L, 2024: DC_OCEAN: an open-source algorithm for identification of duplicates in ocean databases. *Front. Mar. Sci. 11. https://doi.org/10.3389/fmars.2024.1403175
【Chinese Version 中文版】
在我们的日常生活中,重复数据出现的场景并不少见,例如电子邮件的重复发送、地铁公交卡的重复刷卡操作、银行重复多次转账等等,上述行为可能会导致重复记录的出现,其可能会对信息传达的准确性和一致性产生一定的影响。在海洋科学数据库的建设实施过程中,重复观测记录的出现也不例外。现代海洋科学研究越来越依赖于系统的、高可信度的现场观测数据,准确、可靠的海洋观测数据是建设高质量海洋科学数据库、进行多学科交叉研究的重要基础。但是目前,由于全球和区域海洋数据库众多,重复数据记录一直是数据库管理、数据处理和数据库合并中的一个不可忽视的问题。
中国科学院大气物理研究所海洋与气候团队联合美国、意大利、日本和澳大利亚等团队的研究人员开展了全球海洋现场观察数据集中的重复数据识别问题。由于海洋观测数据有不同的来源,在融合数据时,必须要考虑数据重复的问题,需将重复的数据识别并予以剔除或合并,如何准确识别和删除这些海洋中重复的观测数据,保证数据的唯一性一直是全球各大海洋数据中心的亟待解决的一个关键科学技术问题。
团队使用了多个评判标准定义了准确重复(exact duplicates)、潜在重复(possible duplicates)和非重复数据(non-duplicates) ,并基于结合加权平均、熵权法和主成分分析方法研发了一套包括准确重复检查、廓线逐层检查、插值检查等多个模块的重复数据检查系统 (DC_OCEAN) ,用于识别数据集中的重复廓线,保证了海洋观测数据的唯一性。
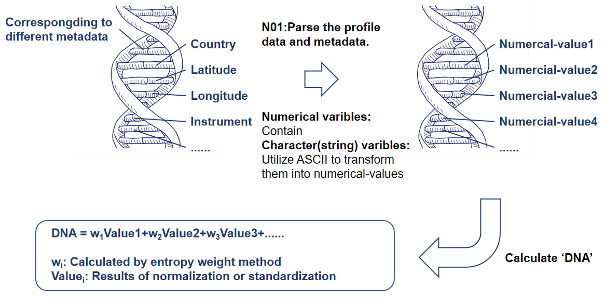
简单来说,DC_OCEAN将每一条海洋观测廓线比作一条生物学上的DNA。廓线中的观测数据和元数据信息就像是这条DNA上的不同片段。通过统计方法,可以计算出一个“唯一识别码”,在这个系统中称为“廓线总得分(profile summary score)”。如果两条“DNA”计算出的廓线总得分相近,甚至相同,就说明它们可能是具有重复数据的特征——这就像双胞胎姐妹的DNA大部分是一样的,表明它们有很多共同特征(图1)。
随后,利用世界海洋数据库(WOD)中1975年、1995年、2011年的数据,团队成员对重复性检查系统进行了测试和评估,并经过国际质量控制海洋数据库计划(IQuOD)的专家的人工二次检查,确认了该系统可以将数据集中大部分的重复数据检测出来(图2)。基于剔除重复数据前后的数据集,团队成员重建了历史海洋温度格点场。发现在西北太平洋地区,1995 年的最大温度差异可达 0.06 ℃(上层 100 m)和 0.05 ℃(上层 300 m),表明重复数据可能会对区域尺度的海洋温度(和海洋热含量)估计产生潜在影响。

这一系统目前已经被纳入到了IQuOD和中科院大气物理研究所的数据质量控制系统中,表明了 DC_OCEAN的实用性和领先性。此外,团队还将该系统的重复性检查结果以基准数据集的形式面向全球公开发布(http://dx.doi.org/10.12157/IOCAS.20230821.001),可以作为未来进一步解决海洋观测重复性问题的新方法和新标杆。
本研究已于2024年10月2日公开发表在《Frontiers in Marine Science》期刊上,作者团队包括来自中国、美国、意大利、日本和澳大利亚五个国家的11位作者。论文共同第一作者是中科院大气所硕士研究生宋欣燚和中科院大气所博士毕业生谭哲韬,通讯作者为中国科学院大气物理研究所成里京研究员。合作作者包括美国国家环境信息中心(NOAA) Locarnini, R. 和Boyer, T.; 意大利国家地球物理和火山研究所 (INGV) Simoncelli, S. 和Reseghetti, F.; 澳大利亚联邦科学与工业研究组织 (CSIRO) 环境气候科学中心Cowley, R.; 日本东北大学地球物理系物理海洋学实验室Kizu, S.; 美国斯克里普斯海洋研究所 (SIO) Castelao, G.; 中国科学院大气物理研究所Gouretski, V.。
本研究得到了国家自然科学基金(42122046, 42076202)、SCOR 委员会和美国国家科学基金会(OCE-1546580)、政府间海洋学委员会(IOC)的国际海洋数据和信息交换(IODE)计划的资助
Recommended citation: Song X†, Tan Z†, Locarnini R, Simoncelli S, Cowley R, Kizu S, Boyer T, Reseghetti F, Castelao G, Gouretski V, Cheng L, 2024: DC_OCEAN: an open-source algorithm for identification of duplicates in ocean databases. Front. Mar. Sci. 11.
Download Paper